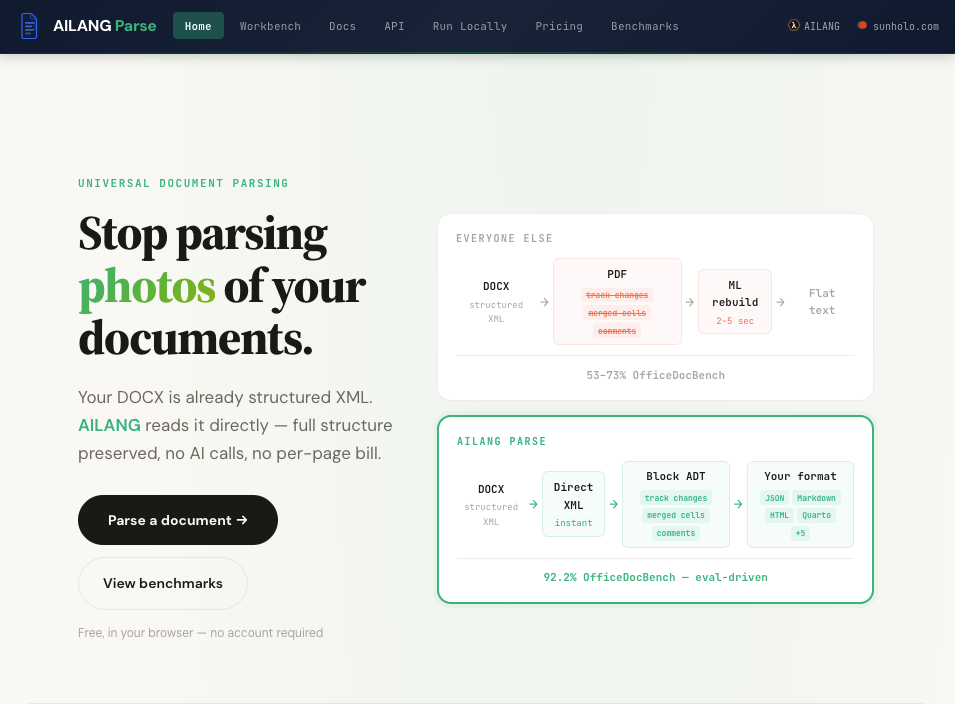
Most tools convert your DOCX to a photo first.
Your DOCX, PPTX, and XLSX files are already structured XML. Every heading, cell, comment, and track change is explicitly labeled in the file. But the dominant approach in 2026 is still to convert Office documents to PDF, render them as images, then run OCR and vision models to guess the structure back out.
That approach:
- Destroys structure that was already there -- merged cells flatten, track changes disappear, comments vanish
- Bills per page at $0.001-$0.01, making high-volume pipelines expensive
- Relies on AI inference for what should be deterministic parsing
- Hallucinates content where OCR confidence is low