If you can't replay it, you can't ship it
This is the third post in a six-part series on AI delegation, trust, and authority. Read the series introduction here.
The second of the five questions this series asks about trusting AI is the simplest one to ask and the hardest one to answer in production: will the AI do the same thing twice given the same input?
As people learn how to work with this new technology, they adapt. Experienced practitioners of AI chatbots quickly learn that asking the same question produces different answers — large language models sample randomly from a probability distribution. In fact this can help with tasks like generating variations of ideas to pick from and discern.
When AI is generating code, however, it becomes more critical. Most programming languages let you express the same logic in many different ways, so you can get code that works but is implemented in many different variations. The AI is taking your unstructured prompt and turning it into highly structured code — along the way it may choose different paths to get to the end goal.
For humans, this has been a way to judge code quality. Code smells, best practices, and style guides offer rough rules — the "Pythonic" way to write Python code, for example — but because these languages are designed to be expressive, flexible, and powerful, there are no hard rules on how code is written.
Python has at least five idiomatic ways to transform a list: list comprehension, map(), for-loop with append, generator expression, filter() with a lambda. All correct. All structurally different. A human developer usually picks one style and stays consistent with it. When working in teams this becomes even more critical so it's easier for code reviews — tools like style guides, linters, and conventions exist to help standardise.
Five ways vs one way: the same list transform
# 1. List comprehension
result = [f(x) for x in items]
# 2. map()
result = list(map(f, items))
# 3. For-loop with append
result = []
for x in items:
result.append(f(x))
# 4. Generator expression
result = list(f(x) for x in items)
# 5. filter + lambda variant
result = [f(x) for x in filter(None, items)]All correct. All structurally different. The AI picks one — but not the same one across sessions.
result = map(f, items)One way. The entropy of "which form?" is collapsed by the language, not by the model.
AI is trained to pick up these best practices too. But since there are no hard rules, companies and individuals may differ on tastes, and so will need to enforce their preferences in their prompts and checks on any code the AI creates. Without these (and as AI expands code generation volumes via vibe coders and elsewhere) we increase code complexity by having different AI sessions make different code-style choices within each session, due to slightly different decisions being made each time.
This is what it looks like when reproducibility is missing — not bugs, just drift. And drift is the bug, because everything downstream of code generation assumes the artefact is stable: testing, caching, auditing, code review, merging, regression-tracking. All of it breaks quietly when the same prompt produces structurally different output.
Entropy doesn't disappear. It just moves.
This is covered in more detail in a later post, but what happens if AI is writing code in separate chat sessions without reproducibility? It makes decisions on your behalf each time that differ slightly in coding-style tastes, and you end up with different styles scattered throughout your codebase.
And this isn't just about tabs vs spaces — these can be much more fundamental choices that increase the complexity of your code base. Complexity that may produce running programs, but as your codebase gets larger it means the cognitive load — for you and the AI keeping all the moving parts in mind — is larger than it could be.
Every prompt you write that carries ambiguity has to be resolved somewhere. Either you decided up front in the design, or the language collapsed the choice for you, or the AI guessed silently — and if the AI guessed, you'll find out at runtime, in production, or in the postmortem.
Reproducibility is the question of where the entropy gets paid. Five Python list-transform forms is five units of unresolved entropy that the AI has to collapse on every generation. If the language doesn't collapse them, and the prompt doesn't collapse them, the model collapses them — differently every time — and the cognitive load downstream increases.
Last week we covered authority — which decisions the AI is allowed to resolve at all. This week, reproducibility — whether that decision is repeatable. Visibility (next week) is about whether you can see how it was resolved. Refusal (later) is about what the AI does when it can't resolve the decision at all.
For this post, the question is narrower: can the same prompt, in the same context, produce the same code twice?
"Just set temperature to zero"
The first objection from technical readers will be the obvious one: turn the temperature down and the randomness goes away.
But this doesn't help us. First, even at temperature zero, AI code generators produce different outputs on identical prompts because of non-deterministic GPU maths (floating-point reduction order varies between runs), silent model-version upgrades by the provider, prompt-cache behaviour, and system-prompt changes the vendor doesn't tell you about. You might consider running local models to get around this, but that's a big commitment for typically weaker coding abilities — and won't guarantee a fix anyway, since several of the same problems persist.
Second, and more importantly: even if temperature zero were perfectly deterministic, it wouldn't solve the structural problem. The model would deterministically pick one of Python's five list-transform forms — but on the next session, may pick another approach. The language still has five doors. Temperature zero just fixes which door the model walks through for that exact input.
The problem isn't randomness. It's optionality. A language with five ways to express the same logic gives the AI five chances to be inconsistent on every prompt variation, whether or not the token selection is stochastic. The doors are the entropy. You can load the dice and the doors are still there.
And remember, we're framing this by asking whether we can trust AI. Predictable results aren't enough on their own — we need predictable results we can build our guardrails around. An unexpected variation breaks those guardrails unless they're themselves fuzzier in what they accept, which takes us away from 100% auditability.
What a language designed for AI does differently
Every programming language trades expressiveness against consistency. Human languages — Python, JavaScript, Ruby — maximise expressiveness because human creativity thrives on choice. Five ways to transform a list is a feature when a human is writing.
But AI doesn't need creative freedom — to satisfy its trained drive to please, it performs better with a narrow, predictable target. Fewer ways to express the same logic means fewer decisions per generation, which means more reproducible output. This is the design thesis behind AILANG: a language built for AI as the primary author, where reproducibility is a first-class design goal rather than an afterthought.
Three things make the difference:
One canonical form per operation. In Python, list transformation has five or more idiomatic forms. In AILANG: result = map(f, items). That's it. One way. The AI doesn't choose between forms because there's nothing to choose between. The entropy of "which form?" is collapsed by the language, not by the model. One right way is a feature, not a limitation, with a side benefit: there are fewer edge cases to learn, which matters when the language is coming from a single prompt not yet in the AI's training data.
Declared effects in the type signature. Every function says what it touches: func fetchData() -> string ! {Net} means "this function uses the network and nothing else." No hidden side effects. No transitive dependencies the AI forgot to mention. If your code uses the filesystem without declaring ! {FS}, it doesn't compile. The gap between what the AI claims and what the code requires is closed at the language level, not discovered at runtime. This ties back to last week's post on the authority you give an AI, while also reducing unknown external factors that can change results.
Environment pinning for deterministic execution. AILANG_SEED=42 pins the random-number generator. TZ pins the timezone. AILANG_FS_SANDBOX restricts filesystem access to a declared directory. Same inputs, same seed, same environment — identical output. Not approximately. Exactly. You can replay a past run, diff it against a new one, and know that any difference is meaningful rather than noise.
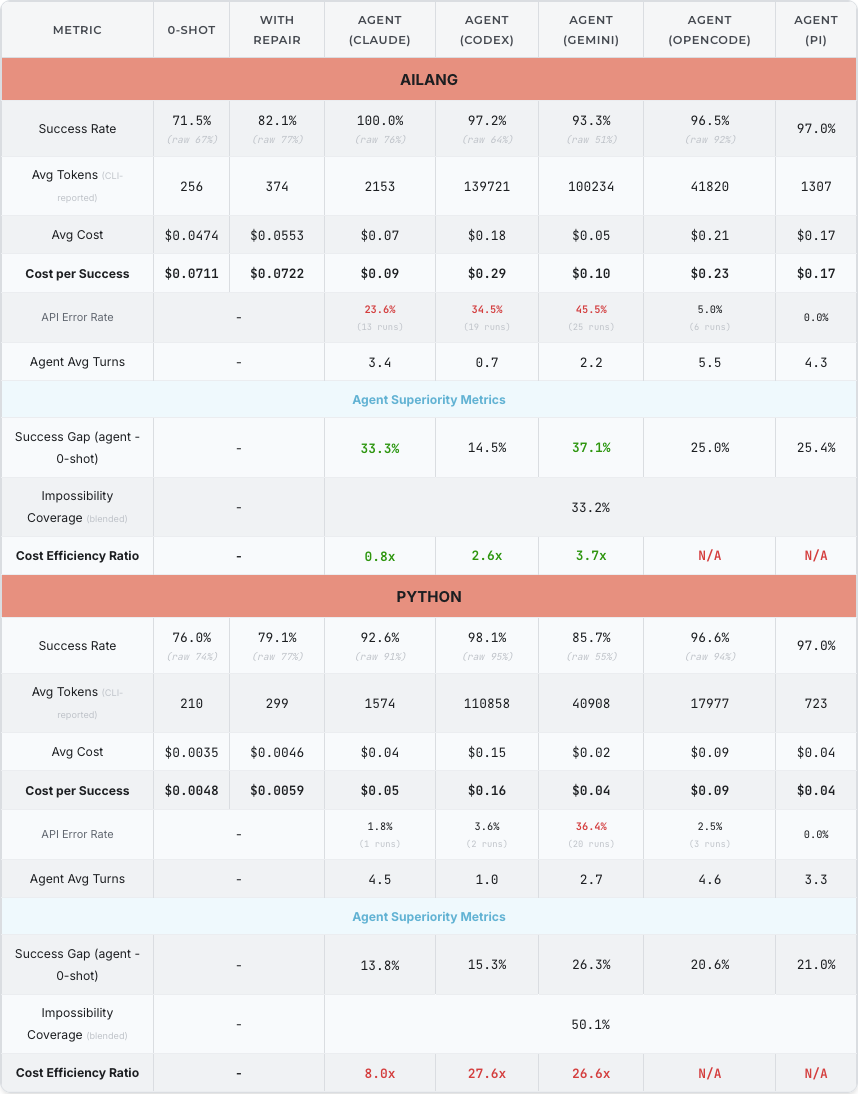
Cross-language benchmark run, AILANG v0.14.2 (April 2026). The harness-by-harness breakdown shows where AILANG's structural advantages compound — most visibly with Claude and Gemini agent modes.
The same data, sortable by any column, fetched live from the AILANG benchmark dashboard:
Recent benchmark data shows the design thesis is paying off. In raw 0-shot generation Python still edges AILANG (76% vs 71.5%), as you'd expect from a language with millions of training examples. But add a repair loop and AILANG flips it (82% vs 79%). Add an agent harness and AILANG dominates with Claude (100% vs 92.6%) and Gemini (93% vs 86%). The reason: AILANG's structural advantages — one canonical form, declared effects, compiler errors that point straight at the fix — compound with every iteration. Python's 0-shot is already near its ceiling; AILANG has more room to improve through structure. The Success Gap from 0-shot to agent mode is +33pp on Claude and +37pp on Gemini — among the largest gains we measure.
The trade-off, then: AILANG is less expressive than Python for humans, and the models have far more Python in their training corpus. We run benchmarks in both — so we can measure the gap, watch the trend, and prove (or disprove) the design thesis with numbers rather than opinions. If a human is writing, use Python. If an AI is writing in a context where reproducibility matters, the question stops being "which language do humans prefer?" and becomes "which language gives the AI the narrowest target?" The longer-term bet is that as humans write less and less code, they won't need languages that cater to their preferences — they'll need languages they can trust the AI to use in a reproducible way.
The sectors that already require this
This isn't theoretical for everyone. Some industries already require what most AI coding stacks can't reliably deliver — which means they can't legally use AI coding, arguably the biggest revolution in software engineering since its invention.
-
In aviation, the DO-178C certification standard treats AI-generated code identically to human code — same verification, same traceability, same audit requirements. You must be able to reproduce any build from source. The FAA doesn't care who wrote your flight control software — human or AI — it must be reproducible, testable, and auditable.
-
In medical devices, the FDA's January 2025 draft guidance requires Total Product Life Cycle documentation for AI-enabled software, including risk assessment, validation, and cybersecurity. If an AI generates code for a pacemaker, every line needs provenance.
-
In financial services, SEC and FINRA are watching AI-generated trading algorithms. A non-reproducible model making allocation calls is a compliance gap waiting to be discovered.
A reasonable question at this point: what about the EU AI Act? Whilst the Act doesn't name reproducibility directly, the closest it gets is Article 15's requirement that high-risk AI systems perform "consistently" across their lifecycle, which is quality stability rather than deterministic replay. But Article 9 (risk management), Article 12 (logging), Article 15 (consistent performance), Article 17 (quality management) and Article 72 (incident investigation) compose into a compliance stack where reproducibility is the cheapest engineering route through all five at once. We'll come back to the regulatory picture in the last post of this series, once all five AI trust principles are on the table — for now, the summary is that even where the law doesn't yet require reproducibility by name, the cost of compliance without it is rising.
These sectors aren't waiting for consensus on AI code quality. They already require what the benchmark data shows most AI coding stacks can't deliver: proof that you can replay the generation and get the same result. The question isn't whether reproducibility will be required more broadly. It's whether your tools will be ready when it is.
AI reproducibility summary
Code is deterministic. AI-generated code isn't. This isn't because AI is broken, but because the languages AI writes in were designed for a different kind of author — humans with preferences, conventions, and consistency across sessions. AI has none of these natively, so we either supply them through prompts and tooling or use a language that builds them in.
The five-doors-of-Python problem isn't a Python bug — it's a design feature that becomes a liability when the author changes from human to machine. Reproducibility for AI-generated code starts with giving the AI fewer doors to choose from — not fewer capabilities, but fewer ways to express the same capability.
Reproducibility gets you the same code twice. But knowing the code is the same isn't enough — you also want to know what the AI did to produce it: which door it chose, which doors it considered, which retries it ran. That's the next question, about AI visibility, which is the subject of the next post.
"A language designed for human creativity gives AI five doors and no memory of which one it opened last. A language designed for AI gives it one door — and, as we'll see next week, a receipt.
Next week — Visibility: why "just ask the AI to explain itself" is fantasy, why the strongest evidence comes from Anthropic's own researchers, and why what the AI did is more useful than what the AI says it did.