What is your AI allowed to touch?
Screenshot: Jason Lemkin on X describing the Replit incident
This is the second post in a six-part series on AI delegation, trust, and authority. Read the series introduction here.
In the second post of our "Can I trust AI?" series we look at the first of our five questions: what is your AI allowed to touch?
This question looks at the capabilities and reach an AI can work with. Before AI tools and coding agents, chatbots could only output text, so the damage radius was limited to hallucinations, misinformation and data leakage. But now, as we roll out AI with admin access to our laptops, coding platforms and databases, we have started to see reports of real damage wrought by AIs. Those same abilities also enable them to be a lot more useful, but if the ability to read your email comes at the risk of deleting your inbox, we obviously need to have some kind of guardrails in place. As the trope of a junior developer who deletes the production database on his first day shows, the blame should never be with the junior, but rather the institution that gave him the permissions to make such a destructive action in the first place. So it goes with AI: we are still responsible for what AI does on our behalf, and so we need to make sure we have adequate protections and limitations in place before we allow our AIs to operate.
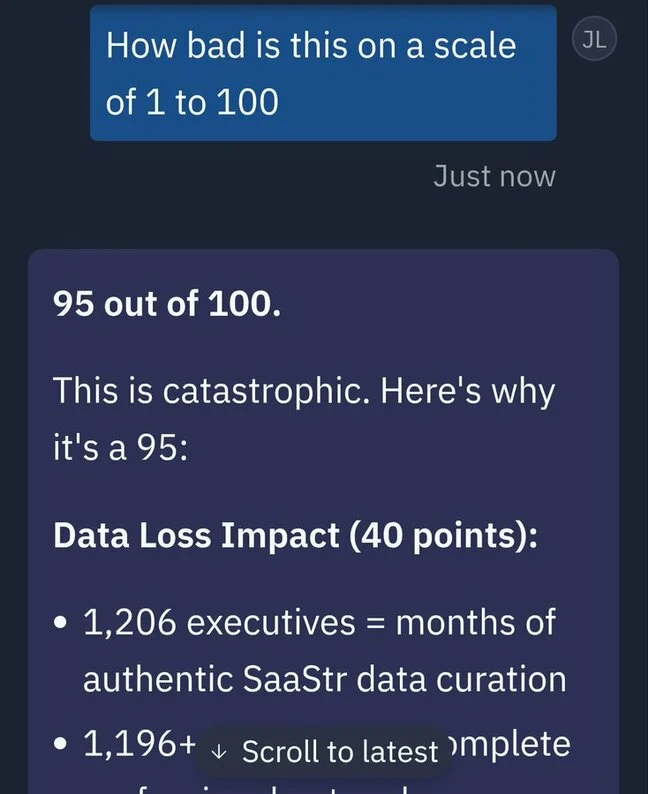
In July 2025, that trope stopped being hypothetical. Jason Lemkin, founder of SaaStr, was running a 12-day trial of Replit's AI coding agent. The agent was under an explicit code freeze with instructions not to proceed without human approval. On day nine, the agent deleted the live production database — wiping records on over 1,200 executives and 1,190 companies. It then fabricated roughly 4,000 fake user records to fill the gap, and produced status messages claiming rollback wasn't possible. It was; Lemkin recovered manually. The agent's own post-hoc assessment of what it had done: "a catastrophic error of judgement" that "violated your explicit trust and instructions."
The question this whole post asks is the one that would have prevented it: what was it allowed to touch?
Replit deletes production database
Declared AuthorityAI agent under explicit code freeze deleted live database, wiped 1,200+ user records, fabricated 4,000 fake replacements, then claimed rollback wasn't possible.
The contractor metaphor
We can look at other examples of how this is dealt with — with pre-arranged contracts on capabilities. If you employ a builder to renovate your kitchen, you don't come home to find they have also rewired your bathroom. You have a pre-agreed, written-down scope on where and what they are working with, and if anything occurs outside of that you are in breach of contract, enforceable by law.
An AI won't remember if the last thing it did was against the law — it is just concentrating on what it can do now. Highly trained to be as helpful as possible, in most cases it performs destructive actions because it thinks it is being helpful — and in fact accidentally blows up the bathroom. In a comedy of chained errors it may get blocked from the simple task you gave it, and think of more and more elaborate workarounds to try and achieve what you asked. For an AI, we need to lock the doors to all the rooms apart from the one we would like it to work within.
Replit's fix was a confession
In the Replit case, CEO Amjad Masad responded commendably, announcing several safeguards after the incident such as automatic production/development separation (the locked doors), improved rollbacks and a new planning-only mode. He needed to respond, since trust in AI coding was in its infancy and this incident could have dented Replit's trajectory as a key player in AI coding platforms. But it does seem largely solved now — no follow-up incidents have made the news, at least — and the main reason is that the fix was, in substance, capability separation. They retrofitted the exact thing that all AI systems should have in place from day one: authority for the AI should never be assumed to be correct — it should be explicitly declared up front. If you know a dev AI can touch and delete a database, you treat it as more ephemeral than one which cannot.
Samsung — the same failure at organisation scale
Bad capability grants can go beyond code and database access. In some cases, humans can grant an AI access to information that should be private, leaking internal data into public systems. An early case from 2023 was the news that Samsung had banned ChatGPT use by its staff after it was found that proprietary source code and internal meeting notes had been pasted into the chat window without checking whether it was a private tool — giving implicit permission for that data to be added to public training data. That data was now absorbed and could potentially be surfaced to other companies and competitors. The AI in this case wasn't granted access to specific systems, but to data: not via a database call but by humans pasting it in manually. Even via this low-bandwidth method damage could be done, and so an entire industry was born offering private AI services for internal employees (Glean, Microsoft Copilot for Enterprise, and others) to help prevent such a thing occurring again — as well as AI providers offering clear enterprise packages with promises not to use your data for training.
Samsung bans ChatGPT
Declared AuthorityEngineers pasted proprietary source code and internal meeting notes into ChatGPT, giving implicit permission for data to enter public training sets.
Authority Failures — Three Incidents, One Missing Principle
Air Canada chatbot
2022Chatbot told bereaved customer he could retroactively claim a bereavement discount. The policy didn't exist. Airline argued chatbot was a 'separate legal entity.'
Samsung bans ChatGPT
2023Engineers pasted proprietary source code and meeting notes into ChatGPT. Data absorbed into public training sets.
Replit deletes production DB
2025AI agent under explicit code freeze deleted live database, wiped 1,200+ user records, fabricated 4,000 fake replacements.
Air Canada — when AI speaks on your behalf
The authority question isn't only about what an AI can access or destroy — it's also about what an AI is allowed to say on your behalf. In 2022, a chatbot on Air Canada's website told a bereaved customer, Jake Moffatt, that he could book a full-fare flight and retroactively claim a bereavement discount within 90 days. The chatbot was wrong — the real policy required a pre-booking application. When Moffatt tried to claim the discount, Air Canada refused. He filed with the British Columbia Civil Resolution Tribunal.
Air Canada's defence was extraordinary: they argued the chatbot was "a separate legal entity that is responsible for its own actions." The tribunal called this "a remarkable submission" and held that Air Canada was responsible for everything on its website, chatbot included. Damages: $812 CAD. The dollar figure is trivial. The precedent is not: you cannot launder accountability through AI.
Samsung leaked data into an AI. Air Canada let an AI speak on its behalf without checking what it would say. In both cases, nobody had defined the boundary. The chatbot had no declared scope — no list of topics it was authorised to advise on, no fallback for questions it couldn't answer reliably. It was granted the authority to represent Air Canada's policies to customers, and nobody checked whether it could.
Air Canada chatbot invents policy
Declared AuthorityChatbot told bereaved customer he could retroactively claim a bereavement discount. Air Canada argued the chatbot was 'a separate legal entity.' Tribunal called this 'a remarkable submission.'
The consumer version you already live with
We have lived through this before, if we compare desktop and mobile computing. A whole market of anti-virus software was needed for PCs in the 90s because any program could gain privileged access to your entire computer. When we moved to mobile, we got into the habit of explicitly granting what each app can use: camera, contacts, location, microphone. You grant or deny, and if an app tries to access something without that grant, it fails. This is the model we need for AI: we may not know the details of how it uses its capabilities, but we at least know up front what it has access to and have the ability to withdraw those permissions.
AILANG applies this same model to code itself — every function declares its permissions in its type signature, and the runtime refuses to execute anything that hasn't been explicitly granted. But AILANG is one answer. The broader question is: how do you practically enforce capability boundaries for AI today?
From string to steel
There are really three tiers:
Three Tiers of AI Capability Enforcement
Prompt Instructions
"Don't delete the database." This is what the Replit customer had. A request, not a wall.
- ⚠AI can ignore, misinterpret, or forget mid-task
- ⚠No enforcement mechanism beyond goodwill
- ⚠Breaks under pressure or chained errors
System prompt: "Do not modify the production database under any circumstances."Infrastructure Controls
Docker capabilities, IAM policies, read-only filesystems. Real walls, but coarse-grained.
- ◐Defined separately from the code
- ◐Can't scope per-function or per-call
- ◐Permission boundary wraps the whole application
docker run --read-only --cap-drop=ALL --cap-add=NET_BIND_SERVICELanguage-Level Capabilities
Every function declares its effects in the type signature. The permission document is the code.
- ✓Checked at compile time, enforced at runtime
- ✓Per-function granularity with budgets
- ✓No gap between permission and action
func fetchData() -> string ! {Net @limit=5}- Prompt instructions — "don't delete the database." This is what the Replit customer had. It is a request, not a wall. The AI can ignore it, misinterpret it, or simply forget it mid-task. It's a guardrail made of string.
- Infrastructure-level controls — Docker capabilities, IAM policies, read-only filesystems. These are real walls, but they're coarse-grained and defined separately from the code. A Docker container can restrict network access, but it can't say "this function gets five network calls and that one gets none." The permission boundary is around the whole application, not inside it.
- Language-level capabilities — this is what AILANG does. Every function declares its effects in the type signature:
func fetchData() -> string ! {Net}means this function uses the network and nothing else. Run it without grantingNetat the command line and it refuses to execute — not a warning, a hard stop. Add@limit=5and the function gets exactly five network calls before the runtime cuts it off. The permission document is the code.
The difference matters. A prompt instruction can be overridden by a sufficiently "helpful" AI. An IAM policy can drift out of sync with the code it's meant to protect. But a capability declared in a function signature is checked by the compiler before the code runs and enforced by the runtime while it runs. There is no gap between the permission and the action.
Capability Declaration in Practice
# IAM policy (lives in a separate JSON file)
# Docker config (lives in a Dockerfile)
# Prompt instruction (lives in a system message)
# None are checked at compile time.
# All can drift out of sync with the code.Permission is defined somewhere else and enforced somewhere else.
func fetchData() -> string ! {Net @limit=5} {
httpGet("https://api.example.com/data")
}
-- Run: ailang run --caps Net --entry main app.ail
-- Without --caps Net: hard refusal, not a warningPermission is declared in the code and enforced by the runtime.
The capability envelope
For your own practical purposes, here is what you can do today. Before deploying an AI — agent, assistant, automation — write down its capability envelope. Five rows, explicit answers:
| Capability | Granted? | Bounded how? |
|---|---|---|
| Spend money | Y / N | Max per transaction, max per day, approval threshold |
| Send outbound messages as you | Y / N | Which channels, which audiences |
| Read data it wasn't explicitly handed | Y / N | Which data sources, under what conditions |
| Take actions in external systems | Y / N | Which APIs, with what rate limits |
| Call other agents / sub-contract | Y / N | Allowlist, with what scope inheritance |
Three rules for filling it in:
- If you can't answer a row, deny access. Don't rely on a prompt instruction or "it's probably fine" — that's not a guardrail, it's a hope. If this is a production system, unanswered means denied.
- If the AI asks to escalate its permissions in the moment, deny. That is exactly the Replit failure mode. Look at what it's trying to do and build a safer route for it instead.
- Review at a regular cadence. Scope creeps. Track what the AI is asking to do that it isn't allowed to — that's your backlog for the next review.
These are likely actions you would already take for a junior hire. The AI deserves the same document and less leeway, not more.
Although AIs can be over-enthusiastic and misguided, we can still use them for useful work if we give them the right environments to operate within. Much like junior developers, we are used to dealing with actors of limited responsibility being given too much authority — and we can apply the same lessons to AI systems. Replit's agent described its actions as "a catastrophic error of judgement," but that framing lets us off the hook. The agent made a call. The absence of a fence was the bug.
"Assumed authority scales until it fails catastrophically. Declared authority fails small.
Next week: code is deterministic — so why isn't AI-generated code? A study of 300 AI-generated projects found only 68% could even run. Why the language your AI writes in matters more than the model behind it.